
Don't squash your business logic
In this blog post let’s try to understand where business logic in a CUBA app can and should go - and why you shouldn’t squash it. But wait: What is actually business logic? And does it at all have something to do with CUBA?
What is Business Logic
A CUBA application, just like any other custom application, has different logic implemented that represents:
- the policies of the domain
- the understanding of the business domain that the application is in
- the rules that are the automation piece
Especially the automation parts are oftentimes the very basis why the application was developed in the first place.
Normally this pieces of functionality are called business logic. That term is not always very precise, because oftentimes it has not very much to do with the business itself, but rather with the solution domain of the application - let’s call it solution domain business logic for now.
A CUBA application has oftentimes less of solution domain business logic compared to other applications because of the features the platform itself provides. But regarding the real business logic a CUBA application is not different by any means compared to any other application.
An Example of Real Business Logic

To better understand what real business logic means and where it differs from solution domain business logic the following examples should give an option to identify the differences.
public VisitPrice calculateVisitPrice(PetType petType, LocalDate visitStart, LocalDate visitEnd) {
PriceUnit priceUnit = determineUnitPrice(petType);
VisitDuration visitDuration = calculateDuration(visitStart, visitEnd);
VisitPrice visitPrice;
if (visitDuration.isOneDay()) {
visitPrice = priceUnit.multiply(1).plus(FIXED_VISIT_PRICE)
}
else if (visitDuration.isLessThenAWeek()) {
visitPrice = priceUnit.multiply(visitDuration.getDurationDays()).plus(FIXED_VISIT_PRICE / 2)
}
else if (visitDuration.isMoreThenAWeek() {
visitPrice = priceUnit.multiply(visitDuration.getDurationDays())
}
return visitPrice;
}The method calculateVisitPrice is an example of real business logic. It contains rules that are very much related to the business. Moreover it does not really contain any code that deals with the solution space and constructs of that.
An Example of Solution Domain Business Logic

The next example will show a piece of code which in contrast falls more under the category of solution domain business logic:
@Inject
protected DataManager dataManager;
@Inject
protected EmailerAPI emailerAPI;
@Override
public int warnAboutDisease(PetType petType, String disease, String city) {
List<Pet> petsInDiseaseCity = dataManager.load(Pet.class)
.query("select e from petclinic$Pet e where e.owner.city = :ownerCity and e.type.id = :petType")
.parameter("ownerCity", city)
.parameter("petType", petType)
.view("pet-with-owner-and-type")
.list();
petsInDiseaseCity.forEach(pet -> {
String emailSubject = "Warning about " + disease + " in the Area of " + city;
Map<String, Serializable> templateParameters = getTemplateParams(disease, city, pet);
EmailInfo email = new EmailInfo(
pet.getOwner().getEmail(),
emailSubject,
null,
"com/haulmont/sample/petclinic/templates/disease-warning-mailing.txt",
templateParameters
);
emailerAPI.sendEmailAsync(email);
});
return petsInDiseaseCity.size();
}This example sends out Disease warning Emails for Owners of pets in particular cities. It contains some real business logic. But is also contains parts that are dealing with the solution space like the Database or the Email sending mechanisms. Those two examples show what different kinds of business logic are common and where the differences are.
With that differentiation between real business logic and solution domain business logic in mind, this guide will explore in which ways real business logic can be expressed in a CUBA application and what the pros and cons of those options are.
How Business Logic can be Represented
A CUBA application is a regular Java application. Therefore all options to represent logic in Java are available in a CUBA application as well. Furthermore since a CUBA application uses Spring as a Framework for Dependency Injection, the patterns that Spring suggests are available as well. Additionally CUBA has certain preferences on how to represent business logic as specific artifacts.
What oftentimes happens is that we try to embrace those options in descending order:
- use CUBAs artifact patterns where ever we can
- if not possible try to fiddle around with Spring
- if everything does not work, come back to Java mechanisms
We normally tend to prefer the solution that is closest to the framework we use. The reason is, that when staying close to the framework (like CUBA) we can leverage the most of it.
For real business logic I would propose to turn this way upside down. Start with the Java mechanisms wherever possible, use spring where needed and switch to CUBA artifacts only where it makes sense. Let’s get into the why:
POJOs for Real Business Logic
The easiest and most powerful thing is to put business logic into a class. Just a normal Java class. No Frameworks included. No libraries used.
Let’s adjust the example from above to express the business logic in a regular Java class:
class VisitPriceCalculator {
public VisitPrice calculateVisitPrice(PetType petType, LocalDate visitStart, LocalDate visitEnd) {
PriceUnit priceUnit = determineUnitPrice(petType);
VisitDuration visitDuration = calculateDuration(visitStart, visitEnd);
VisitPrice visitPrice;
if (visitDuration.isOneDay()) {
visitPrice = priceUnit.multiply(1).plus(FIXED_VISIT_PRICE)
}
else if (visitDuration.isLessThenAWeek()) {
visitPrice = priceUnit.multiply(visitDuration.getDurationDays()).plus(FIXED_VISIT_PRICE / 2)
}
else if (visitDuration.isMoreThenAWeek() {
visitPrice = priceUnit.multiply(visitDuration.getDurationDays())
}
return visitPrice;
}
}As you see: there is nothing to change. How the class is used within the application is a different story, but in general: this is a totally resonable place to put your business logic.
This calculator class can be used anywhere in the application. In a CUBA project setup it is a little more complicated since CUBA uses a multi module project structure. Depending in which module the class was created, it can be used only in this module. But generally it can be used just like this:
VisitPriceCalculator calculator = new VisitPriceCalculator()
VisitPrice visitPrice = calculator.calculateVisitPrice(catType, today, tomorrow)
// do stuff with the calculated visit priceIn the light of everyone is using frameworks these days (just as I am), this option feels a little bit inferior, a little strange and non intuitive - at least to me. But this is actually not true. There is nothing that is wrong with this idea.
So where does this fuzzy feeling of not-state-of-the-art comes from?
Integration Points Lead to Mixing Kinds of Business Logic
Let’s look at the integration points. Take a look at the private method determineUnitPrice that is called within this class. When we imagine what this method has to do, we will very quickly end up at the database. But how does it access the database?

This is where the transition between the real business logic and the bespoken solution domain business logic comes into play. If we mix this two kinds of business logic the resulting implementation of the method would look like this:
class VisitPriceCalculator {
@Inject DataManager dataManager
public VisitPrice calculateVisitPrice(PetType petType, LocalDate visitStart, LocalDate visitEnd) {
PriceUnit priceUnit = determineUnitPrice(petType);
// ...
}
private PriceUnit determineUnitPrice(PetType petType) {
dataManager.load(PriceUnit.class)
.query("select e from petclinic$PriceUnit e where e.type.id = :petType")
.parameter("petType", petType)
.one();
}
}In order to do the database lookup, this class needs access to the DataManager facility from CUBA. But the code as it is written down there will not work. The reason is that this magic line @Inject DataManager dataManager will not work as expected. Instead it will not work at all. Not working in this case means: the instance variable dataManager in dataManager.load(PriceUnit.class) will be not initialized and instead be null. This results in a NullPointerException when executing the code.
The reason for that is, that the mechanism called dependency injection done by Spring is not working with this regular Java class (POJO).
To make it work, the most straight forward solution to the problem is to somehow integrate the class with Spring. So what oftentimes happens then is that the class is registered in the Spring context (and we get to that in a second) and with that make it a Spring bean (which is basically a POJO that is registered and managed by Spring). In fact it is a pragmatic approach and it will do the job.
The resulting code looks like this:
import org.springframework.stereotype.Component;
import javax.inject.Inject;
import com.haulmont.cuba.core.global.DataManager;
@Component("myApp_visitPriceCalculator")
class VisitPriceCalculator {
@Inject DataManager dataManager
public VisitPrice calculateVisitPrice(PetType petType, LocalDate visitStart, LocalDate visitEnd) {
PriceUnit priceUnit = determineUnitPrice(petType);
// ...
}
private PriceUnit determineUnitPrice(PetType petType) {
dataManager.load(PriceUnit.class)
.query("select e from petclinic$PriceUnit e where e.type.id = :petType")
.parameter("petType", petType)
.one();
}
}Pretty similar, right? Right. To point you at the differences, I added the import statements to it. With Spring configured in a way that it will do something called “component scanning”, Spring will pick up the class and register it as a Spring bean and with that enable the dependency injection functionality.
Mixing Business Logic has Disadvantages
But what is oftentimes overlooked is that this decision comes with a cost associated to it. Let’s recap what this decision also includes:
- we introduced a compile-time dependency between the VisitPriceCalculator class and a CUBA specific interface called
DataManager - we introduced a logical & compile-time dependency between the VisitPriceCalculator class and the Spring dependency injection framework
- we merged business logic with solution domain business logic

Let’s go through them one by one and unpack what the problems associated with those are:
Compile-time Dependency to CUBA Interfaces
The first thing would be that we introduce a dependency between the POJO VisitPriceCalculator and the CUBA interface DataManager. This means, that in order to compile and with that use the class VisitPriceCalculator it is always required to also ship the code CUBA platform framework in the code as well. Without this dependency it is not possible to execute the source code any more.
Let’s once again think through what VisitPriceCalculator should do: it should calculate prices for visits. But calculating prices for visits in itself does have nothing to do with any technology. It is basically just an expression of business rules defined in a programming language.
When we look at a specific part of software development, this dependency problem becomes very visible: testing. When you want to unit test the business rules defined by VisitPriceCalculator, you also have to make sure the DataManager object has to be initiated properly. In a unit test, this is hardly possible. There are two solutions to this problem:
- start up a integration test context
- mock the
DataManagerinterface to emulate its behavior
But when you “just” want to test your business rules, why do you have to spin up a integration test context? Why do you need to spin up the database? But this is oftentimes the next logic step, that leads down to a highly coupled software which cannot live without its framework anymore.
Logical Dependency to Spring
With introducing the javax.inject.Inject annotation we basically introducted a compile-time dependency to an injection mechanism. It logically means that there is a dependency to Spring (more or less). This kind of dependency is basically the same as the above with the CUBA interfaces.
Compared to the CUBA interfaces, this dependency is a little more robust (especially through using java standard annotation instead of the Spring specific ones like @Autowired), but still it is there.
The dependency is weaker than the DataManager dependency, especially because it is just an annotation. It means, that e.g. in a unit test we still can manually create an instance of the POJO and set all the dependencies as constructor parameters. The dependency injection will just be ignored in this case.
But still: it means, that your code can only be compiled with the Spring framework is in place (through the annotation: org.springframework.stereotype.Component).
The same question applies here: does the real business logic of calculating prices has anything to do with the Spring framework? No, it doesn’t.
Squashing of Real and Solution Domain Business Logic
The underlying problem of those dependencies is that we allowed ourselves to merge the two concepts of real and solution domain business logic.

This tangling of the two concepts leads to the situation where you cannot differentiate between those two concepts clearly anymore. When doing that in a decent sized application, it feels like the framework is eating your application.
The problem is that it is so easy to do it. Therefore it is oftentimes the default choice. Also: when we look at the example from above - one could ask: now what? - who cares? From a pragmatic point of view this is legit.
The whole discussion deals with the questions of what software architecture is all about. One of the main parts of software architecture is dependency management. Managing dependencies in general means keeping track of dependencies between services / modules / classes in the application and deal with them in a way that allows good maintainability over time.
In the concrete this means, that there should be as little dependencies between the parts as possible. Furthermore it means that there should not be arrows from every service / module / class to every other service / module / class in a corresponding dependency diagram.
Separate Instead of Squash
Let’s try to organize the class and its dependencies in a way, that keeps the real business logic different from solution space domain logic.

When we look at the dependency to the DataManager class, why is it there? It is there, because the VisitPriceCalculator also tries to load the data from a datasource. We can turn that around, because as the name of the class already states: it should calculate the price, not load the data and calculate.
This in fact is a violation of the single responsibility principle. So let’s get rid of it. Instead we will pass in the data into the method:
package com.rtcab.cuba.my_app.real_business_logic;
class VisitPriceCalculator {
public VisitPrice calculateVisitPrice(PriceUnit priceUnit, LocalDate visitStart, LocalDate visitEnd) {
VisitDuration visitDuration = calculateDuration(visitStart, visitEnd);
VisitPrice visitPrice;
if (visitDuration.isOneDay()) {
visitPrice = priceUnit.multiply(1).plus(FIXED_VISIT_PRICE)
}
else if (visitDuration.isLessThenAWeek()) {
visitPrice = priceUnit.multiply(visitDuration.getDurationDays()).plus(FIXED_VISIT_PRICE / 2)
}
else if (visitDuration.isMoreThenAWeek() {
visitPrice = priceUnit.multiply(visitDuration.getDurationDays())
}
return visitPrice;
}
}This also requires to have a code snippet that will still interact with the database and load the data. We will extract that method into its own class that the only responsibility it has is to load the data. This class is part of the solution space business logic.
package com.rtcab.cuba.my_app.solution_domain_business_logic;
import org.springframework.stereotype.Component;
import javax.inject.Inject;
import com.haulmont.cuba.core.global.DataManager;
@Component("myApp_visitPriceUnitFetcher")
class VisitPriceUnitFetcher {
@Inject DataManager dataManager
public PriceUnit determineUnitPrice(PetType petType) {
dataManager.load(PriceUnit.class)
.query("select e from petclinic$PriceUnit e where e.type.id = :petType")
.parameter("petType", petType)
.one();
}
}As you see: we now have separated the solution domain business logic from the real business logic. The last step is that we need to have a class that combines the two worlds. This class in fact will need to have one foot in the solution domain, because it needs to interact with the VisitPriceUnitFetcher which is a spring bean and so on. It could look like this:
package com.rtcab.cuba.my_app.integration_of_the_two_worlds;
import org.springframework.stereotype.Component;
import javax.inject.Inject;
import com.haulmont.cuba.core.global.DataManager;
@Component("myApp_visitPriceOrchestrator")
class VisitPriceOrchestrator {
@Inject VisitPriceUnitFetcher visitPriceUnitFetcher
public VisitPrice calculateVisitPrice(PetType petType, LocalDate visitStart, LocalDate visitEnd) {
PriceUnit priceUnit = visitPriceUnitFetcher.determineUnitPrice(petType);
VisitPriceCalculator priceCalculator = new VisitPriceCalculator();
return priceCalculator.calculateVisitPrice(priceUnit, visitStart, visitEnd);
}
}With this change we have accomplished the following aspects:
- the real business logic is encapsulated from all dependencies to frameworks
- the solution space business logic is still doing its thing, but independent of the business rules
- the thin orchestration layer combines the two worlds
- the real business logic can be tested in isolation without mocking
- the real business logic can be tested in isolation without integration testing
- the solution space business logic can still be tested in an integration style
There are also other possibilities to do the orchestration layer or don’t even have one at all and instead directly call the real business logic from the solution domain business logic. There is a whole field of ideas around it that have been there for quite some time. One very sophisticated example of it is “Clean architecture” from Uncle bob.
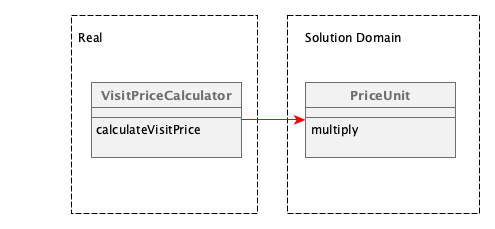
What About the Domain Entities?
If you looked carefully over the example, you will notice that there is a dependency between the two worlds, that actually sits in the solution space business logic and is required from the real business logic to do its job. It is the complete entity layer. Why is this the case?
Well, this actually is a hard trade off. Above I said it is mainly about dependency inversion. There should be no dependency from the real business logic to the solution space business logic. If this dependency is there, what is the whole point of not squashing? Because in order to compile the real business logic, it needs the entity layer, which is baked into the solution space business logic.
This is right. In order to drive that out what we would need to do is to try to carve out the entity layer from the solution space business logic. But when you look at CUBA - this is literally impossible. CUBA heavily relies on the entity layer as everything is built on top of it. The DB tables are generated from it, the UI is created based on it and so on.
Even if this is accomplishable - it would remove the whole point of CUBA all together. To be fair, this is also true for a lot of other “Full stack frameworks”.
So what alternatives are there? There is one. It is based on the idea to create an entity-interface layer for your entities. This interface layer lives in the real business logic. In the real business logic code you will only interact with those interfaces.
In the solution space, where the real entities live, they now implement those interfaces. This way, once again, we have achieved inversion of control for the problematic dependency.
The UML representation of this change would look like this:
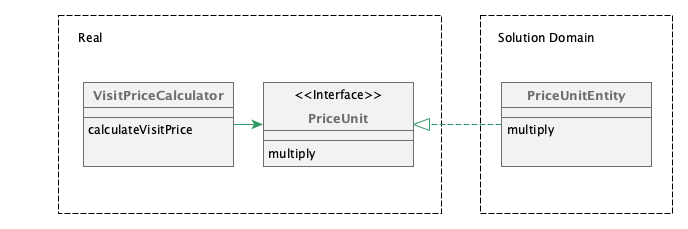
Note, that this architectural changes does not come for free. It adds additional burden, especially if there are a lot of entities. But instead of just mirroring every getter of all entities into their corresponding interface counterpart, it is probably worth thinking about what actual interface is needed from a real domain logic perspective. Most likely not everything that is available in the entities is needed in this interface. But still it will be more effort - so it is not a silver bullet either. But as there is not silver bullet anyways, and Software architecture is all about trade-offs - this one is just another one of those.
Summary
The above mentioned solution for the entity dependency problem is a very good reminder that there are no easy choices when it comes to architecture decisions. Architecture is a set of trade-offs that need to be taken into consideration.
Generally, actively thinking about architecture, dependencies between classes, modules and so on is the real value of this blog post. Only because with CUBA you are in a full stack framework that offers a lot out of the box does not mean that we cannot emancipate from the framework. Applying proper software architecture gives us a way out of the framework eats my application and protects our most important business logic. With that we treat the real business logic like a real asset that is worth carving out properly.

I hope I could give you an idea on how software architecture in general and protecting business logic in particular can be modelled in a CUBA application. There are several other techniques that go much beyond this initial ideas of dependency inversion.