
Test and seed data in CUBA applications
One thing that is a kind of an evergreen in application development is the question about how to inject seed and / or test data into the system. In this blog post, we will have a look on how this topic is covered in CUBA-land and what we can possibly do to extend the functionality.
General options for data import / export
When we look at what general options are availiable in a normal CUBA application, at least the following list comes to my mind:
- JSON based im- / export of entity instances through the entity inspector
- SQL based export for entity instances through “System information” –> “Insert script”
- SQL / groovy based import through DB scripts that are run in the init phase (like 30.create-db.sql)
- REST JSON im- / export for entity instances through the generic REST API
There are other valid options that aren’t that integrated into the CUBA platform as well, but we will not cover these in details.
If I got it correctly, the JSON based im- / export has been added later to the platform and therefore can be seen as the newer version of the SQL based approach. So let’s see where the differences lie and what the benefits each approach brings to the table.
| Feature | JSON based | SQL based |
|---|---|---|
| automatic load at startup | ☐ | ☑ |
| distinction between seed data and test data | ☑ | ☐ |
| export multiple instances | ☑ | ☐ |
| association support | ☑ | ☑ |
| DBMS independent | ☑ | ☐ |
| API syntax | ☑ | ☐ |
As we can see, both options have their advantages. But the main reason for using the SQL based approach is because there is already a mechanism to bootstrap this data with the idea of the DB init scripts.
The problem with this approach though is that you can’t really use this feature if you want to distinguish between data, that is necessary for production usage: seed data and data that is used for your internal test systems, e.g. which might be part of the codebase, but should not leak into production. This is not always necessary, like when you separate the test data from your application code and insert the data via a REST API, e.g. after the application has started, but sometimes it can be handy to have the test data alongside with the code.
Enable automatic JSON load at startup
Let’s try to enhance the JSON based approach, so that instead of having to manually import the data after the application started, the JSON files will be picked up at application start just like the DB init scripts do.
For this, I created an example application: cuba-example-json-testdata. In this example there is mainly one class that handles the JSON import: JsonDataImporter. It implements mainly one lifecycle method from the AppContext.Listener interface: applicationStarted() which allows the application developer to execute arbitrary code on application startup.
The import mainly consists of the following code:
@Override
public void applicationStarted() {
importData(SEEDDATA_FILE_PATTERN);
if (globalConfig.testMode) {
importData(TESTDATA_FILE_PATTERN)
}
}
void importData(String filePattern) {
authentication.begin();
try {
Resource[] zipResources = loadResources(filePattern).sort { it.filename }
zipResources.each { resource ->
importTestdataForResource(resource)
}
} finally {
authentication.end();
}
}
Resource[] loadResources(String pattern) throws IOException {
ResourcePatternUtils.getResourcePatternResolver(resources).getResources(pattern);
}
void importTestdataForResource(Resource resource) {
def entityClass = determineEntityClass(resource)
if (entityClass) {
EntityImportView entityImportView = createEntityImportViewForEntityClass(entityClass)
byte[] zipBytes = IOUtils.toByteArray(resource.getInputStream());
entityImportExportService.importEntities(zipBytes, entityImportView);
}
}
MetaClass determineEntityClass(Resource resource) {
// return the right meta class...
}
EntityImportView createEntityImportViewForEntityClass(MetaClass entityClass) {
if (entityClass.getName() == 'sec$Group') {
return createGroupsImportView()
} else if (entityClass.getName() == 'sec$Role') {
return createRolesImportView()
} else {
return createEntityImportView(entityClass);
}
}
EntityImportView createEntityImportView(MetaClass metaClass) {
EntityImportView entityImportView = new EntityImportView(metaClass.getJavaClass());
for (MetaProperty metaProperty : metaClass.getProperties()) {
switch (metaProperty.getType()) {
case MetaProperty.Type.DATATYPE:
case MetaProperty.Type.ENUM:
if (!metaProperty.annotatedElement.isAnnotationPresent(com.haulmont.chile.core.annotations.MetaProperty)) {
entityImportView.addProperty(metaProperty.getName());
}
break;
case MetaProperty.Type.ASSOCIATION:
case MetaProperty.Type.COMPOSITION:
if (!metaProperty.getRange().getCardinality().isMany()) {
entityImportView.addProperty(metaProperty.getName(), ReferenceImportBehaviour.IGNORE_MISSING);
}
break;
default:
throw new IllegalStateException("unknown property type");
}
}
return entityImportView;
}
EntityImportView createGroupsImportView() { /* a little bit different */}
EntityImportView createRolesImportView() { /* a little bit different */}importData imports all JSON files that match a particular pattern. To do this, it uses the Resources abstraction within the loadResources method together with the ResourcePatternResolver from Spring to get all Resources for the given pattern.
Next, the importTestdataForResource does the actual job for a particular resource. To do so, it firstly determines the entity class from the Resource filename through the corresponding method determineEntityClass. Next, it has to create a EntityImportView for the resource. This class acts like a mask on the actual data that has to be imported and defines what attributes will be included in the import, if there are required attributes etc.
After the preconditions are met, the actual import is provided by another platform facility: EntityImportExportService. This serice takes the zip file and an EntityImportView instance to do the actual import in the db. It is used in the generic entity inspector import / export feature e.g. For Groups and Roles there is another EntityImportView created, for the full code, you can look at the implementation of the JsonDataImporter.
Exporting the data from the running application
After we created the facility to add data into the system, let’s have a look on how to actually create the data. One common way to do so is to use the built-in feature of the platform: to im- / export the data via the generic CUBA UI.
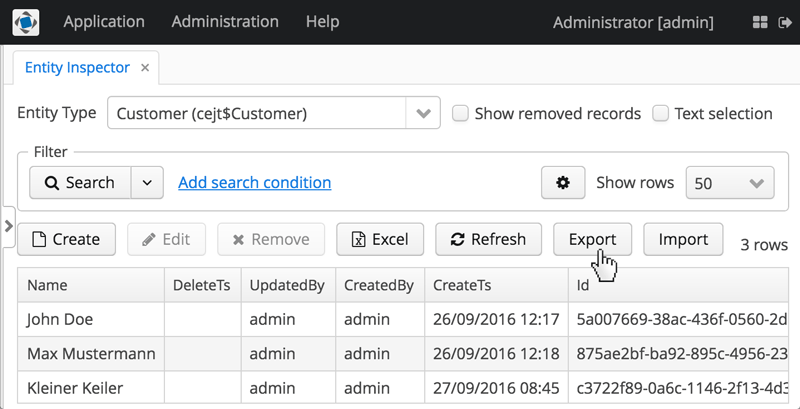
You can either select a single or multiple instances and click export. Then, the required zip file containing the JSON entity definitions will be downloaded. We just have to put it into the right directory to get it automatically picked up from the JsonDataImporter.
But before doing that, here is one thing you should be aware of. In the entity inspector, only the direct attributes and references to other objects are exported. So when you want to export related attributes as well, you have to select every entity explicitly. An example of this would be the User to Role relationship sec$UserRole.
This seems to be one reason why the CUBA folks created a few export / import buttons for particular platform entities (like Roles and Security Groups) in the corresponding browse screens. In the Groups browse screen, the export functionality not just exports the Group instance, but also its constraint references and session attributes.
Importing the extracted data
The actual data has to be placed in the data directory of the core module so that it gets picked up. As described above in this example, I created an distinction between test and seed data. To decide if the application should only import the seed data or the test data directory as well, we can reuse the application property: cuba.testMode.
So in this case, not only the normal test mode for the cuba application is configured, which allows easier functional testing, but also test data is loaded so that the functional tests can be executed on preconfigured data. Obviously nothing prevents us from using this testMode for manual testing as well, so the functional test and manual test will share the test data in this case.
The filename of the zip file should follow the following convention, so that the JsonDataImporter is able to pick it up: #nr#-#entityName#-#description#.zip
- nr is just for ordering purposes
- entityName should be the value of the @Entity annotation, where the $ is replaced by _
- description a description of the content of the file
Some gotchas on the data import
As the JsonDataImporter (in the current implementation) is executed on every startup of the application server, the data gets imported again and again. Since the IDs are the part of the JSON file, it will not append the same data in the DB, but instead act like a reset on these instances. Whenever an instance is changed through the user or the system itself while the application is running - the next server restart will reset the data to its original state. It could be fixed (depending on your use case, this might be a bug or not) with another configuration option, where the instance is checked for existence in the DB and in case it will not import the instance again.
In case you want to auto load application properties that are stored in the DB (with the sys$Config entity) through this mechanism, it will not work like you might expect. The data will get loaded in the DB correctly, but as the application server has already started when importing the data, it will not pick up the application properties before the next restart. Just to keep in mind. A solution to this might be to either do a restart or to load these application properties data through the SQL approach.
With this we covered a fairly small solution to a problem, to make the JSON import a little bit better than it already is. I hope you enjoyed it! If you have questions and or ideas for optimization of this, let me know.